![]()
Latest [May 24, 2024] Databricks-Certified-Data-Engineer-Associate Exam Dumps - Valid and Updated Dumps
Free Sales Ending Soon - 100% Valid Databricks-Certified-Data-Engineer-Associate Exam Dumps with 90 Questions
Databricks-Certified-Data-Engineer-Associate certification is a valuable credential for data engineers. It demonstrates to potential employers that the individual has the skills and knowledge necessary to design and implement data-driven solutions using Databricks. Databricks Certified Data Engineer Associate Exam certification can also help individuals advance their careers by opening up new opportunities and increasing their earning potential.
The GAQM Databricks-Certified-Data-Engineer-Associate (Databricks Certified Data Engineer Associate) Certification Exam is a comprehensive examination that tests the skills of professionals who work with data on the Databricks platform. Databricks Certified Data Engineer Associate Exam certification is designed to help professionals stay up-to-date with the latest data engineering trends and technologies, and it can help professionals advance their career in the field of data engineering. By earning this certification, professionals can demonstrate their commitment to professional development and their dedication to staying current in their field.
NEW QUESTION # 45
A single Job runs two notebooks as two separate tasks. A data engineer has noticed that one of the notebooks is running slowly in the Job's current run. The data engineer asks a tech lead for help in identifying why this might be the case.
Which of the following approaches can the tech lead use to identify why the notebook is running slowly as part of the Job?
- A. They can navigate to the Tasks tab in the Jobs UI and click on the active run to review the processing notebook.
- B. There is no way to determine why a Job task is running slowly.
- C. They can navigate to the Runs tab in the Jobs UI and click on the active run to review the processing notebook.
- D. They can navigate to the Tasks tab in the Jobs UI to immediately review the processing notebook.
- E. They can navigate to the Runs tab in the Jobs UI to immediately review the processing notebook.
Answer: C
Explanation:
Explanation
The job run details page contains job output and links to logs, including information about the success or failure of each task in the job run. You can access job run details from the Runs tab for the job. To view job run details from the Runs tab, click the link for the run in the Start time column in the runs list view. To return to the Runs tab for the job, click the Job ID value.
If the job contains multiple tasks, click a task to view task run details, including:
the cluster that ran the task
the Spark UI for the task
logs for the task
metrics for the task
https://docs.databricks.com/en/workflows/jobs/monitor-job-runs.html#job-run-details
NEW QUESTION # 46
A data engineering team has two tables. The first table march_transactions is a collection of all retail transactions in the month of March. The second table april_transactions is a collection of all retail transactions in the month of April. There are no duplicate records between the tables.
Which of the following commands should be run to create a new table all_transactions that contains all records from march_transactions and april_transactions without duplicate records?
- A. CREATE TABLE all_transactions AS
SELECT * FROM march_transactions
INNER JOIN SELECT * FROM april_transactions; - B. CREATE TABLE all_transactions AS
SELECT * FROM march_transactions
MERGE SELECT * FROM april_transactions; - C. CREATE TABLE all_transactions AS
SELECT * FROM march_transactions
OUTER JOIN SELECT * FROM april_transactions; - D. CREATE TABLE all_transactions AS
SELECT * FROM march_transactions
INTERSECT SELECT * from april_transactions; - E. CREATE TABLE all_transactions AS
SELECT * FROM march_transactions
UNION SELECT * FROM april_transactions;
Answer: E
Explanation:
Explanation
To create a new table all_transactions that contains all records from march_transactions and april_transactions without duplicate records, you should use the UNION operator, as shown in option B. This operator combines the result sets of the two tables while automatically removing duplicate records.
NEW QUESTION # 47
A single Job runs two notebooks as two separate tasks. A data engineer has noticed that one of the notebooks is running slowly in the Job's current run. The data engineer asks a tech lead for help in identifying why this might be the case.
Which of the following approaches can the tech lead use to identify why the notebook is running slowly as part of the Job?
- A. They can navigate to the Tasks tab in the Jobs UI and click on the active run to review the processing notebook.
- B. There is no way to determine why a Job task is running slowly.
- C. They can navigate to the Runs tab in the Jobs UI and click on the active run to review the processing notebook.
- D. They can navigate to the Tasks tab in the Jobs UI to immediately review the processing notebook.
- E. They can navigate to the Runs tab in the Jobs UI to immediately review the processing notebook.
Answer: A
Explanation:
The Tasks tab in the Jobs UI shows the list of tasks that are part of a job, and allows the user to view the details of each task, such as the notebook path, the cluster configuration, the run status, and the duration. By clicking on the active run of a task, the user can access the Spark UI, the notebook output, and the logs of the task. These can help the user to identify the performance bottlenecks and errors in the task. The Runs tab in the Jobs UI only shows the summary of the job runs, such as the start time, the end time, the trigger, and the status. It does not provide the details of the individual tasks within a job run. References: Jobs UI, Monitor running jobs with a Job Run dashboard, How to optimize jobs performance
NEW QUESTION # 48
A data engineer has left the organization. The data team needs to transfer ownership of the data engineer's Delta tables to a new data engineer. The new data engineer is the lead engineer on the data team.
Assuming the original data engineer no longer has access, which of the following individuals must be the one to transfer ownership of the Delta tables in Data Explorer?
- A. Original data engineer
- B. This transfer is not possible
- C. Databricks account representative
- D. Workspace administrator
- E. New lead data engineer
Answer: D
Explanation:
Explanation
https://docs.databricks.com/sql/admin/transfer-ownership.html
NEW QUESTION # 49
A data engineer is working with two tables. Each of these tables is displayed below in its entirety.
The data engineer runs the following query to join these tables together:
Which of the following will be returned by the above query?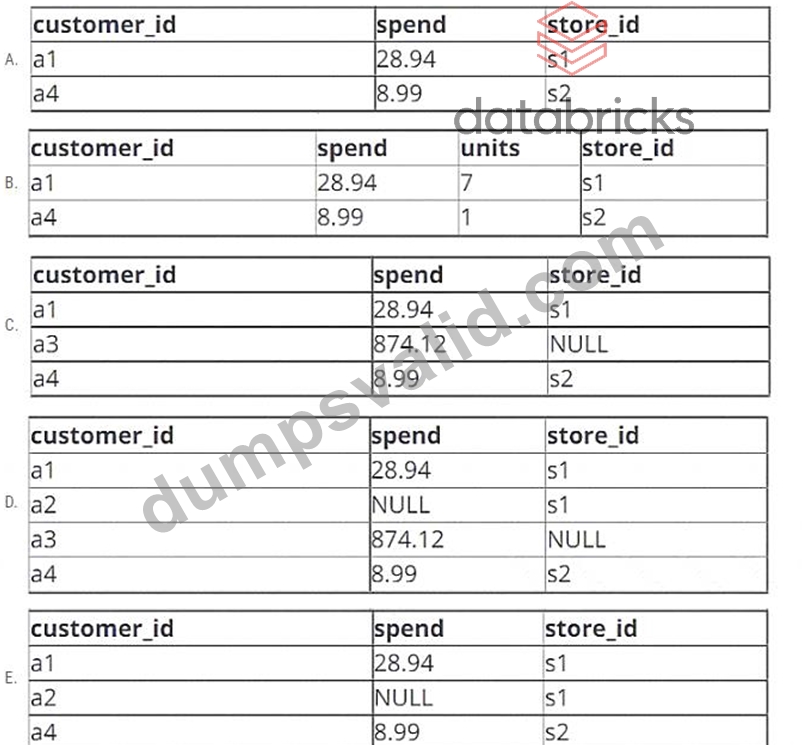
- A. Option D
- B. Option A
- C. Option B
- D. Option E
- E. Option C
Answer: E
NEW QUESTION # 50
A dataset has been defined using Delta Live Tables and includes an expectations clause:
CONSTRAINT valid_timestamp EXPECT (timestamp > '2020-01-01') ON VIOLATION DROP ROW What is the expected behavior when a batch of data containing data that violates these constraints is processed?
- A. Records that violate the expectation are added to the target dataset and recorded as invalid in the event log.
- B. Records that violate the expectation are dropped from the target dataset and recorded as invalid in the event log.
- C. Records that violate the expectation are dropped from the target dataset and loaded into a quarantine table.
- D. Records that violate the expectation are added to the target dataset and flagged as invalid in a field added to the target dataset.
- E. Records that violate the expectation cause the job to fail.
Answer: B
Explanation:
Explanation
With the defined constraint and expectation clause, when a batch of data is processed, any records that violate the expectation (in this case, where the timestamp is not greater than '2020-01-01') will be dropped from the target dataset. These dropped records will also be recorded as invalid in the event log, allowing for auditing and tracking of the data quality issues without causing the entire job to fail.
https://docs.databricks.com/en/delta-live-tables/expectations.html
NEW QUESTION # 51
Which of the following commands can be used to write data into a Delta table while avoiding the writing of duplicate records?
- A. IGNORE
- B. MERGE
- C. INSERT
- D. DROP
- E. APPEND
Answer: B
Explanation:
Explanation
To write data into a Delta table while avoiding the writing of duplicate records, you can use the MERGE command. The MERGE command in Delta Lake allows you to combine the ability to insert new records and update existing records in a single atomic operation. The MERGE command compares the data being written with the existing data in the Delta table based on specified matching criteria, typically using a primary key or unique identifier. It then performs conditional actions, such as inserting new records or updating existing records, depending on the comparison results. By using the MERGE command, you can handle the prevention of duplicate records in a more controlled and efficient manner. It allows you to synchronize and reconcile data from different sources while avoiding duplication and ensuring data integrity.
NEW QUESTION # 52
A data engineer is maintaining a data pipeline. Upon data ingestion, the data engineer notices that the source data is starting to have a lower level of quality. The data engineer would like to automate the process of monitoring the quality level.
Which of the following tools can the data engineer use to solve this problem?
- A. Auto Loader
- B. Delta Live Tables
- C. Delta Lake
- D. Data Explorer
- E. Unity Catalog
Answer: C
NEW QUESTION # 53
Which of the following commands will return the number of null values in the member_id column?
- A. SELECT count_if(member_id IS NULL) FROM my_table;
- B. SELECT count_null(member_id) FROM my_table;
- C. SELECT count(member_id) FROM my_table;
- D. SELECT count(member_id) - count_null(member_id) FROM my_table;
- E. SELECT null(member_id) FROM my_table;
Answer: A
Explanation:
Explanation
https://docs.databricks.com/en/sql/language-manual/functions/count.html Returns A BIGINT.
If * is specified also counts row containing NULL values.
If expr are specified counts only rows for which all expr are not NULL.
If DISTINCT duplicate rows are not counted.
NEW QUESTION # 54
A data engineer has configured a Structured Streaming job to read from a table, manipulate the data, and then perform a streaming write into a new table.
The code block used by the data engineer is below:
If the data engineer only wants the query to process all of the available data in as many batches as required, which of the following lines of code should the data engineer use to fill in the blank?
- A. processingTime(1)
- B. trigger(parallelBatch=True)
- C. trigger(availableNow=True)
- D. trigger(continuous="once")
- E. trigger(processingTime="once")
Answer: C
Explanation:
https://spark.apache.org/docs/latest/api/python/reference/pyspark.ss/api/pyspark.sql.streaming.DataStreamWriter
NEW QUESTION # 55
A single Job runs two notebooks as two separate tasks. A data engineer has noticed that one of the notebooks is running slowly in the Job's current run. The data engineer asks a tech lead for help in identifying why this might be the case.
Which of the following approaches can the tech lead use to identify why the notebook is running slowly as part of the Job?
- A. They can navigate to the Tasks tab in the Jobs UI and click on the active run to review the processing notebook.
- B. There is no way to determine why a Job task is running slowly.
- C. They can navigate to the Runs tab in the Jobs UI and click on the active run to review the processing notebook.
- D. They can navigate to the Tasks tab in the Jobs UI to immediately review the processing notebook.
- E. They can navigate to the Runs tab in the Jobs UI to immediately review the processing notebook.
Answer: C
NEW QUESTION # 56
Which of the following benefits is provided by the array functions from Spark SQL?
- A. An ability to work with data within certain partitions and windows
- B. An ability to work with an array of tables for procedural automation
- C. An ability to work with time-related data in specified intervals
- D. An ability to work with complex, nested data ingested from JSON files
- E. An ability to work with data in a variety of types at once
Answer: D
Explanation:
Explanation
Array functions in Spark SQL are primarily used for working with arrays and complex, nested data structures, such as those often encountered when ingesting JSON files. These functions allow you to manipulate and query nested arrays and structures within your data, making it easier to extract and work with specific elements or values within complex data formats. While some of the other options (such as option A for working with different data types) are features of Spark SQL or SQL in general, array functions specifically excel at handling complex, nested data structures like those found in JSON files.
NEW QUESTION # 57
A data analyst has developed a query that runs against Delta table. They want help from the data engineering team to implement a series of tests to ensure the data returned by the query is clean. However, the data engineering team uses Python for its tests rather than SQL.
Which of the following operations could the data engineering team use to run the query and operate with the results in PySpark?
- A. spark.sql
- B. spark.table
- C. spark.delta.table
- D. SELECT * FROM sales
- E. There is no way to share data between PySpark and SQL.
Answer: A
Explanation:
The spark.sql operation allows the data engineering team to run a SQL query and return the result as a PySpark DataFrame. This way, the data engineering team can use the same query that the data analyst has developed and operate with the results in PySpark. For example, the data engineering team can use spark.sql("SELECT * FROM sales") to get a DataFrame of all the records from the sales Delta table, and then apply various tests or transformations using PySpark APIs. The other options are either not valid operations (A, D), not suitable for running a SQL query (B, E), or not returning a DataFrame (A). References: Databricks Documentation - Run SQL queries, Databricks Documentation - Spark SQL and DataFrames.
NEW QUESTION # 58
An engineering manager wants to monitor the performance of a recent project using a Databricks SQL query.
For the first week following the project's release, the managerwants the query results to be updated every minute. However, the manager is concerned that the compute resources used for the query will be left running and cost the organization a lot of money beyond the first week of the project's release.
Which of the following approaches can the engineering team use to ensure the query does not cost the organization any money beyond the first week of the project's release?
- A. They can set the query's refresh schedule to end on a certain date in the query scheduler.
- B. They cannot ensure the query does not cost the organization money beyond the first week of the project's release.
- C. They can set a limit to the number of DBUs that are consumed by the SQL Endpoint.
- D. They can set a limit to the number of individuals that are able to manage the query's refresh schedule.
- E. They can set the query's refresh schedule to end after a certain number of refreshes.
Answer: A
NEW QUESTION # 59
In order for Structured Streaming to reliably track the exact progress of the processing so that it can handle any kind of failure by restarting and/or reprocessing, which of the following two approaches is used by Spark to record the offset range of the data being processed in each trigger?
- A. Checkpointing and Idempotent Sinks
- B. Checkpointing and Write-ahead Logs
- C. Structured Streaming cannot record the offset range of the data being processed in each trigger.
- D. Write-ahead Logs and Idempotent Sinks
- E. Replayable Sources and Idempotent Sinks
Answer: B
Explanation:
Structured Streaming uses checkpointing and write-ahead logs to record the offset range of the data being processed in each trigger. This ensures that the engine can reliably track the exact progress of the processing and handle any kind of failure by restarting and/or reprocessing. Checkpointing is the mechanism of saving the state of a streaming query to fault-tolerant storage (such as HDFS) so that it can be recovered after a failure.
Write-ahead logs are files that record the offset range of the data being processed in each trigger and are written to the checkpoint location before the processing starts. These logs are used to recover the query state and resume processing from the last processed offset range in case of a failure. References: Structured Streaming Programming Guide, Fault Tolerance Semantics
NEW QUESTION # 60
A Delta Live Table pipeline includes two datasets defined using STREAMING LIVE TABLE. Three datasets are defined against Delta Lake table sources using LIVE TABLE.
The table is configured to run in Production mode using the Continuous Pipeline Mode.
Assuming previously unprocessed data exists and all definitions are valid, what is the expected outcome after clicking Start to update the pipeline?
- A. All datasets will be updated at set intervals until the pipeline is shut down. The compute resources will persist to allow for additional testing.
- B. All datasets will be updated once and the pipeline will shut down. The compute resources will be terminated.
- C. All datasets will be updated once and the pipeline will persist without any processing. The compute resources will persist but go unused.
- D. All datasets will be updated once and the pipeline will shut down. The compute resources will persist to allow for additional testing.
- E. All datasets will be updated at set intervals until the pipeline is shut down. The compute resources will be deployed for the update and terminated when the pipeline is stopped.
Answer: E
Explanation:
Explanation
In a Delta Live Table pipeline running in Continuous Pipeline Mode, when you click Start to update the pipeline, the following outcome is expected: All datasets defined using STREAMING LIVE TABLE and LIVE TABLE against Delta Lake table sources will be updated at set intervals. The compute resources will be deployed for the update process and will be active during the execution of the pipeline. The compute resources will be terminated when the pipeline is stopped or shut down. This mode allows for continuous and periodic updates to the datasets as new data arrives or changes in the underlying Delta Lake tables occur. The compute resources are provisioned and utilized during the update intervals to process the data and perform the necessary operations.
NEW QUESTION # 61
......
Databricks-Certified-Data-Engineer-Associate Exam Dumps - 100% Marks In Databricks-Certified-Data-Engineer-Associate Exam: https://examcollection.dumpsvalid.com/Databricks-Certified-Data-Engineer-Associate-brain-dumps.html